前言
在准备OSCP考试之前,以THM平台巩固Web基础及相关。
Web基础-part 1
-
What is DNS?
DNS 指 Domain Name System,即域名系统,DNS能为我们提供一种简单的方式来与互联网上的设备进行通信,而不需要记住复杂的IP地址。
就像每个家庭都有一个唯一的地址能够用来直接发送和接收邮件一样,互联网上的每台计算机也都有自己唯一的地址能够用于通信,这个地址被称为IP地址。
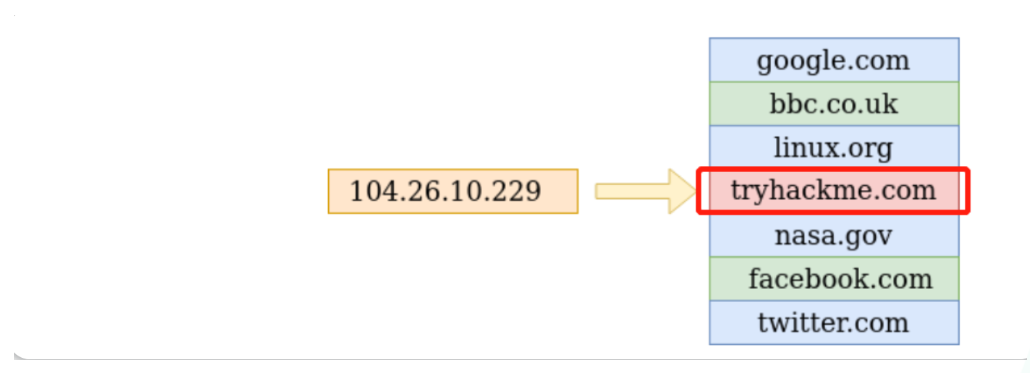
IP地址的格式如下:104.26.10.229,主要由4组0 ~ 255的二进制数字组成,中间用英文句点号隔开。当你想用浏览器来访问一个网站时,选择记住和目标网站相对应的那组复杂的IP地址 可能并不太方便,这就是DNS可以帮助我们的地方。在使用了DNS协议之后,我们就不需要记住类似于 104.26.10.229 的IP地址,而是可以选择记住和IP地址对应的域名如:tryhackme.com 。
-
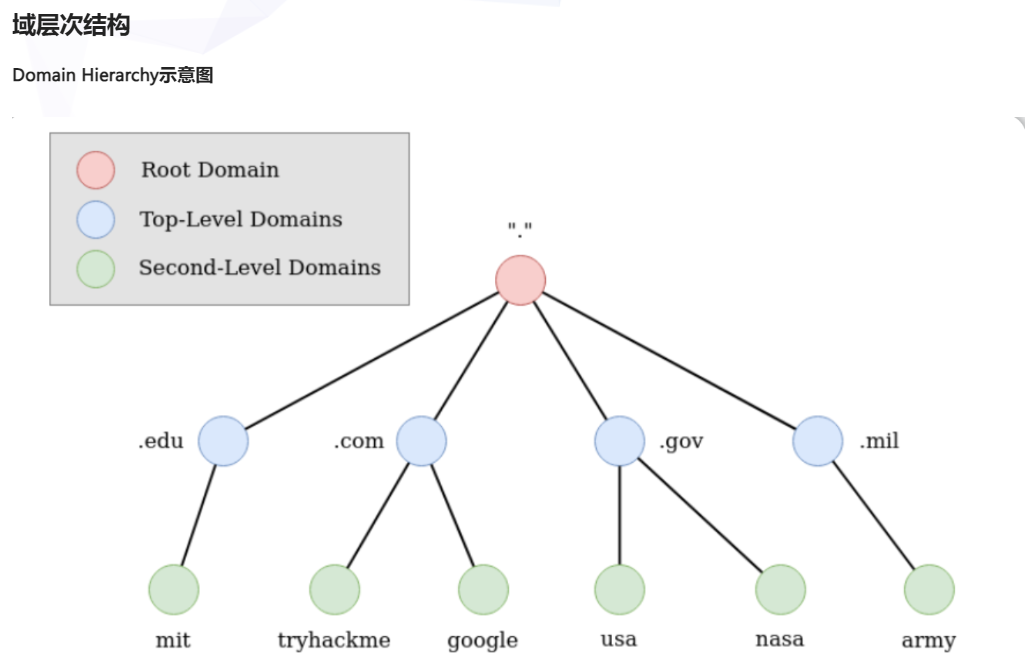
Domain Hierarchy
-
Top-Level Domain(TLD-顶级域)
TLD指的是域名最右边的部分,例如,tryhackme.com的顶级域名是.com;TLD有两种类型,包括gTLD(通用顶级域)和ccTLD(国家代码顶级域)。
在计算机历史上,通用顶级域名主要用于告诉用户“域名的用途”,例如,.com用于商业目的,.org用于组织,.edu用于教育,.gov用于政府;而ccTLD的用途是表示地理位置,例如.ca表示位于加拿大的网站,.co.uk表示位于英国的网站等等。基于用户需求,新的通用顶级域名在大量涌入,包括.online,.club,.website,.biz等等。
要查看超过2000个顶级域名的完整列表,请访问以下链接:
https://data.iana.org/TLD/tlds-alpha-by-domain.txt
tips:gTLD - Generic Top Level、ccTLD - Country Code Top Level Domain 。
-
Second-Level Domain(二级域)
以tryhackme.com为例,.com部分是TLD,tryhackme部分则是二级域名。在进行域名注册时,二级域名被限制最长可使用63个字符+顶级域名(TLD),在具体的二级域名部分只能使用”a-z”、”0-9”和连字符”-“(不能以连字符开头或结尾,也不能使用连续的连字符)。
-
Subdomain(子域)
在一个完整的域名中,子域位于二级域的左侧,两者之间将使用英文句点分隔,例如,在一个域名 admin.tryhackme.com 中,admin部分就是子域。
子域名的创建限制与二级域名相同,都被限制为最长可用63个字符,并且同样只能使用A -z 0-9和连字符(不能以连字符开头或结尾或使用连续连字符)。
在一个域名中,我们可以同时使用多个子域,只要用英文句点分隔即可,由此我们便能创建一个较长的域名,例如 jupiter.servers.tryhackme.com ,但是域名的整体长度必须控制在253个字符以内,也就是说:在域名整体长度没超过限制的情况下,我们可以为一个域名创建多个子域名且无数量限制。
-
-
Record Types(DNS记录类型)
-
A 记录
此类DNS记录将被解析为IPv4地址,例如:104.26.10.229
-
AAAA 记录
此类DNS记录将被解析为IPv6地址,例如:2606:4700:20::681a:be5
-
CNAME 记录
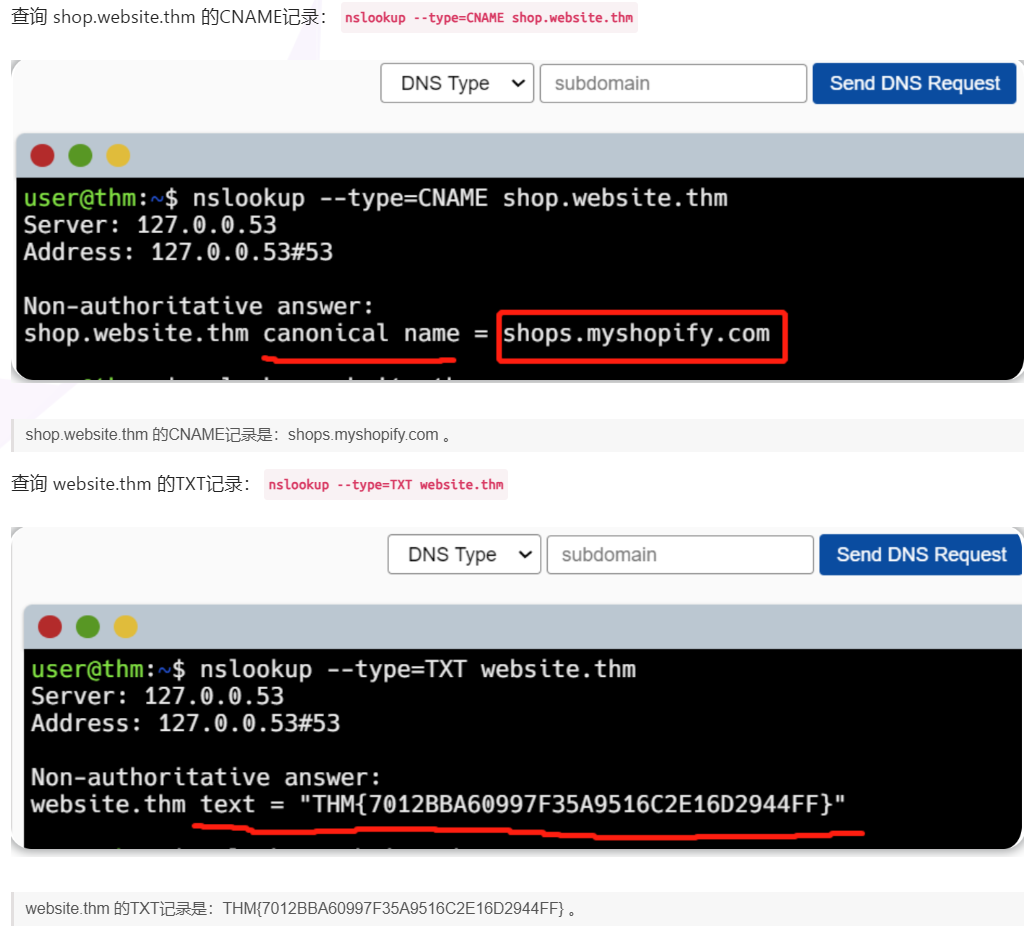
此类DNS记录将被解析到另一个域名,例如,TryHackMe的在线商店有一个子域名store.tryhackme.com,它能返回一个CNAME记录shops.shopify.com,然后再向shops.shopify.com发出另一个DNS请求,就能计算出相关的IP地址。
-
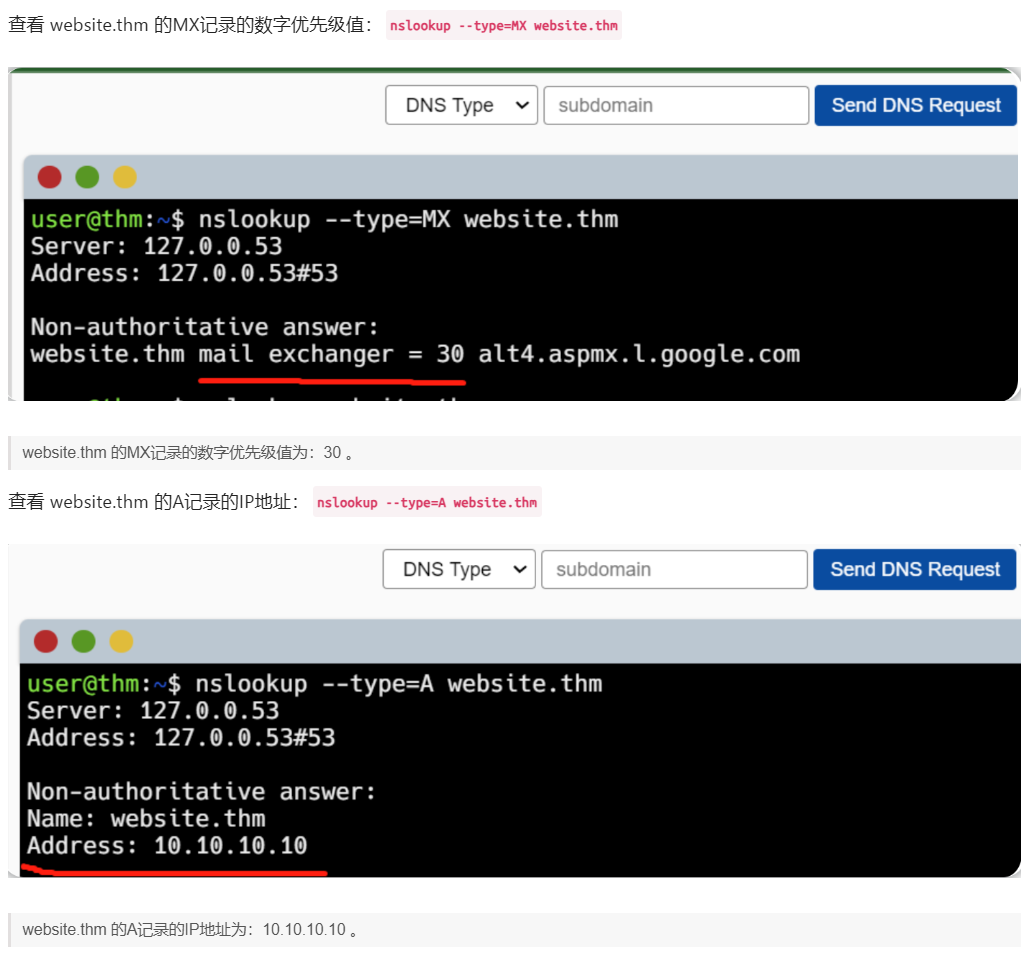
MX 记录
此类DNS记录将被解析为 处理你正在查询的域的电子邮件服务器地址,例如 tryhackme.com 的MX记录响应可能为 alt1.aspmx.l.google.com ;这类记录还会带有一个优先级值,此值将告诉客户端以什么顺序来尝试访问电子邮件服务器,如果主电子邮件服务器宕机,则可以将电子邮件发送到备份电子邮件服务器。
-
TXT 记录
TXT记录是自由文本字段,任何基于文本的数据都可以存储在其中。TXT记录有多种用途,一些常见的用途是 列出有权代表域发送电子邮件的服务器(这可以帮助对抗垃圾邮件和钓鱼邮件),TXT记录还可用于 在注册第三方服务时验证域名的所有权。
-
-
Making A Request
- 当发出DNS请求时会发生什么?
-
当你请求一个域名时,你的计算机首先会检查它自身的本地缓存,看看你最近是否查询过这个地址(即查看缓存中是否已经为目标网站存储了一个相关的 IP 地址),如果发现本地缓存中无相关记录,你的计算机则将向递归(recursive)DNS服务器发送DNS请求。
-
递归DNS服务器通常会由你的Internet 服务提供商(即ISP,在中国是移动、联通等)提供,但你也可以选择一些其他的递归DNS服务器。递归DNS服务器会带有一个关于“最近查找过的域名”的本地缓存,如果在此缓存中找到结果,则相关的信息将被发送回你的计算机,你的DNS请求也会在这里结束(这种域名请求情况对于谷歌、Facebook、Twitter等受欢迎以及域名请求频率很高的网站服务来说很常见)。如果在递归DNS服务器的本地缓存中无法找到域名请求的结果,接下来就会开始从互联网的根DNS服务器尝试寻找关于域名请求的正确答案。
-
根DNS服务器是互联网的DNS主干,它们的工作是将域名请求重定向到正确的顶级域服务器,重定向的结果取决于你的域名请求内容:例如,如果你请求 www.tryhackme.com ,那么根DNS服务器将识别到.com的顶级域名,并会将你指向处理.com地址的正确TLD(顶级域)服务器。
-
TLD服务器会保存“在哪里能找到响应DNS请求的权威服务器”的记录。权威服务器通常也被称为域的名称服务器,例如 www.tryhackme.com 的名称服务器是kip.ns.cloudflare.com和uma.ns.cloudflare.com,一个域名可能会有多个域名服务器,这是为了形成备份以防宕机。(简而言之:当 TLD 服务器收到我们的域名请求时,TLD服务器会将域名请求信息传递给适当的权威名称服务器,而权威名称服务器主要用于直接存储域的 DNS 记录)
-
权威DNS服务器是负责存储特定域名的DNS记录的服务器,并且能对所存储的DNS记录进行及时更新。基于DNS记录的不同类型会有多条DNS记录内容,而这些与你的域名请求相关的DNS记录都存储在权威DNS服务器中,当域名请求到达权威DNS服务器之后,权威DNS服务器会将这些与你的域名请求相关的DNS记录 发送回递归DNS服务器,递归DNS服务器将会为这些DNS记录缓存一个本地副本 以备将来的请求所需,然后这些DNS记录将被转发回 发出域名请求的原始客户端机器。
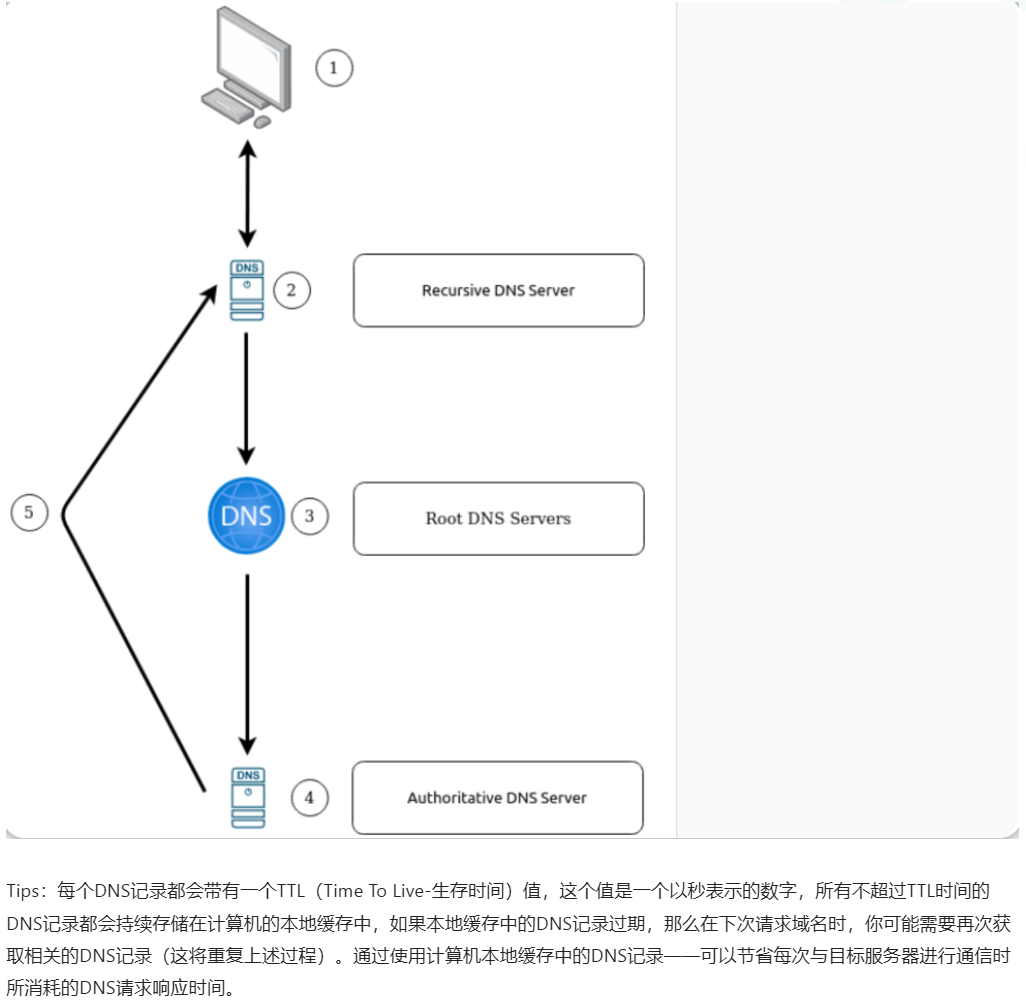
-
Test
Web基础-part 2
-
What is HTTP(S)?
-
什么是HTTP(HyperText Transfer Protocol-超文本传输协议)?
HTTP 是你浏览网站时使用的,由 Tim Berners-Lee 和他的团队在 1989-1991 年间开发。 HTTP 是用于与web服务器进行通信以便传输网页数据的一组规则,这些网页数据包括 HTML、图像、视频等。
-
什么是HTTPS(HyperText Transfer Protocol Secure)?
HTTPS 是 HTTP 的安全版本。 HTTPS 数据经过了加密处理,因此它不仅可以阻止第三方看到你正在接收和发送的数据内容,而且还可以确保你正在与正确的 Web 服务器进行通信(而不是其他冒充你所访问的目标web服务器的东西)。
-
-
Requests And Responses
当我们访问一个网站时,你的浏览器将需要向一个web服务器发出请求,以获得诸如 HTML、图像等资源,并根据来自web服务器的响应得到下载权限。在此之前,你需要明确地告诉浏览器如何获取以及在哪里访问具体的资源文件,这里就需要 URL 来提供一些帮助。
-
什么是 URL? (Uniform Resource Locator)
如果你使用过互联网,那么你就使用过 URL,URL 主要用于指示如何访问互联网上的资源。下面的图片显示了一个 URL 的所有特性(它可能不会在每个请求中使用所有特性)。
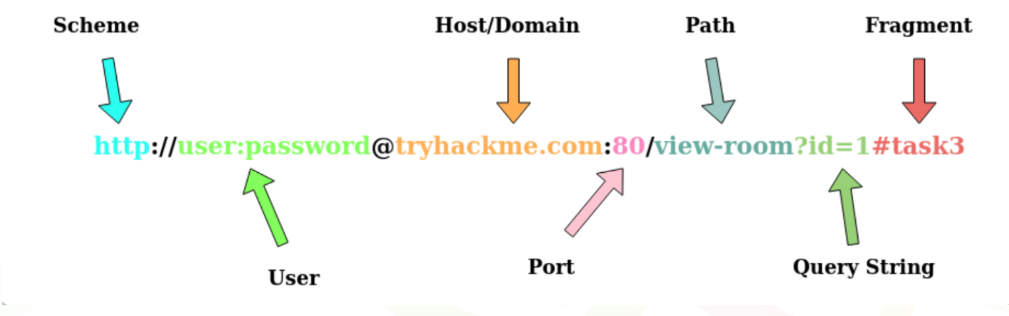
- Scheme:这说明了使用什么协议来访问资源,如HTTP、HTTPS、FTP(文件传输协议)。
- User:有些服务需要认证以完成登录,你可以在URL中输入用户名和密码进行登录。
- Host/Domain:你希望访问的服务器的域名或IP地址。
- Port:你将要连接到的端口,通常HTTP协议将使用 80 端口,HTTPS协议将使用 443 端口,但是这些协议也可以选择使用 1 - 65535 之间的任何端口号。
- Path:你试图访问的资源的文件名或位置。 Query String:可以发送到请求路径的额外信息位。例如,/blog?id =1 将告诉blog path你希望接收id为1的博客文章。
- Fragment:这是对所请求的实际页面上的位置的引用。这通常用于具有较长内容的页面,并且可以将页面的某一部分直接链接到该引用;因此,只要用户通过该URL访问页面,就可以看到链接所对应的部分内容。
-
发出请求
-
只需要一行”GET / HTTP/1.1”就可以向web服务器发出请求。
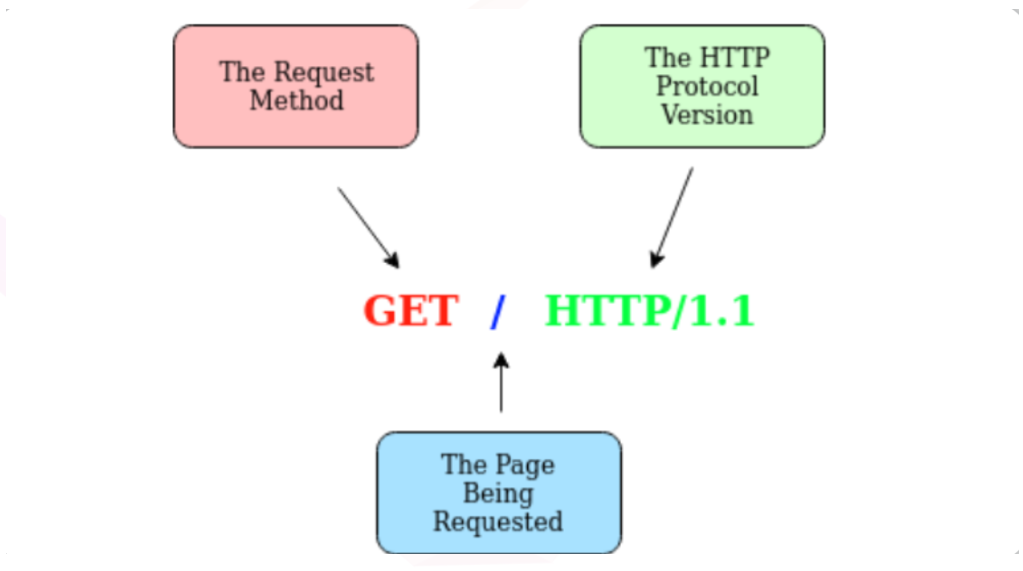
但为了获得更丰富的网络体验,你还需要通过请求消息发送其他数据,这些数据将通过请求报头进行发送,在请求报头中也会包含一些额外的信息,以提供给与你进行通信的web服务器。
- 请求示例(由浏览器客户端发送至服务器端)
GET / HTTP/1.1 Host: tryhackme.com User-Agent: Mozilla/5.0 Firefox/87.0 Referer: https://tryhackme.com/分解以上请求示例的每一行:
第1行:这个请求将发送GET方法(详见本文的HTTP方法小节),用/请求主页,并告诉web服务器我们正在使用的HTTP协议版本为1.1。
第2行:我们将告诉web服务器我们想要访问域名为tryhackme.com的网站。
第3行:我们将告诉web服务器我们正在使用Firefox 87版本浏览器。
第4行:我们正在告诉web服务器,将我们指向当前页面的来源网址(引用页)是https://tryhackme.com
第5行:HTTP请求总是以空行结束,以通知web服务器该HTTP请求已经完成。
- 响应示例(由服务器端发送至浏览器客户端)
HTTP/1.1 200 OK Server: nginx/1.15.8 Date: Fri, 09 Apr 2021 13:34:03 GMT Content-Type: text/html Content-Length: 98 <html> <head> <title>TryHackMe</title> </head> <body> Welcome To TryHackMe.com </body> </html>分解以上响应示例的每一行:
第1行:HTTP 1.1是服务器正在使用的HTTP协议版本,然后是HTTP状态码(在本例中为“200 Ok”),它告诉我们该响应对应的请求已经成功完成。
第2行:这告诉我们web服务器使用的软件和其版本号。
第3行:web服务器的当前日期、时间和时区。
第4行:Content-Type报头会告诉客户端该web服务器将要发送什么类型的信息,比如HTML、图像、视频、pdf、XML。
第5行:Content-Length将告诉客户端该响应的长度,这样我们就可以确认没有发生数据丢失。
第6行:HTTP响应包含一个空行,用于确认HTTP响应的结束。
第7-14行:被请求的信息,在本例中是关于目标主页的html代码
-
-
-
HTTP Methods
HTTP 方法是客户端在发出 HTTP 请求时显示其预期操作的一种方式。有很多 HTTP 方法,在此我们将介绍最常见的方法,在大多数情况下你将处理的是 GET 和 POST 方法。
-
GET 请求:用于从 Web 服务器中获取信息。
-
POST 请求:用于向 Web 服务器提交数据并可能创建新记录。
-
PUT 请求:用于向 Web 服务器提交数据以更新信息。
-
DELETE 请求:用于从Web服务器中删除信息/记录。
-
-
HTTP Status Codes
-
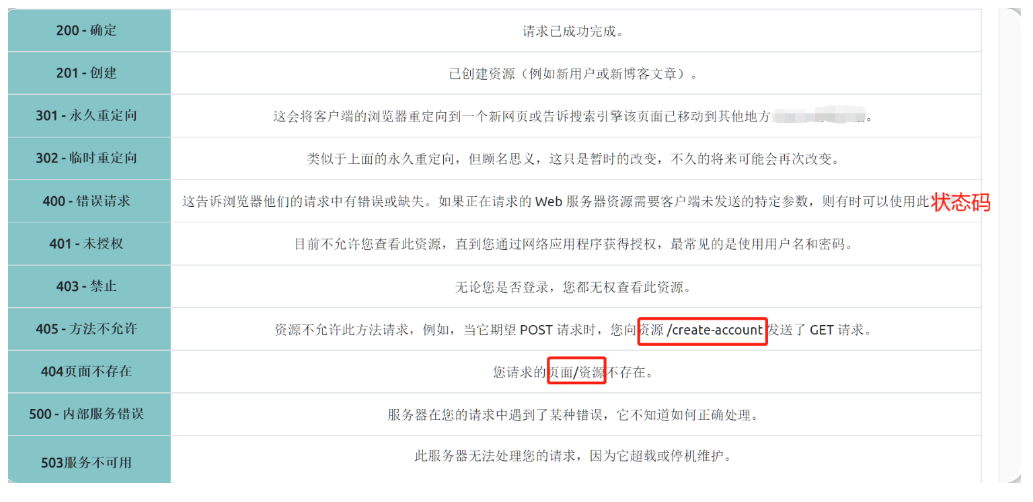
HTTP状态码
在前面的叙述中,能了解到当 HTTP 服务器发出响应时,第一行总是会包含一个状态代码,该状态码用于通知客户端所发出请求对应的结果以及针对请求的可能处理方式。 这些状态码可以分为 5 个不同的范围:

-
常见的HTTP状态码
有很多不同的 HTTP 状态码,这还不包括应用程序自己定义的状态码,可能遇到的最常见的 HTTP 响应状态码:
-
-
Headers(请求标头和响应标头)
标头是你在发出请求时可以发送到 Web 服务器的额外数据位。
虽然在发出 HTTP 请求时没有严格要求标头,但在缺少标头的情况下,你会发现你很难正确地查看网站。
-
常见的请求头
以下是从客户端(通常是你的浏览器)发送到服务器端的标头信息。
-
Host:一些 Web 服务器可能会在多个网站上托管内容,因此通过提供主机标头,你可以告诉web服务器你需要访问哪个网站,否则你只会收到web服务器对应的默认网站的响应。
-
User-Agent:这是你所使用的浏览器软件类型和版本号,告诉web服务器你的浏览器软件类型能帮助它为你的浏览器正确格式化网站,而且网站相关的 HTML、JavaScript 和 CSS 的一些元素只在某些浏览器中可用。
-
Content-Length:当向 Web 服务器发送数据时,例如当浏览器通过表单向web服务器发送数据时,Content-Length将告诉 Web 服务器该 Web 请求所期望的数据长度,这样web服务器就可以确保它在响应浏览器请求时并不会丢失任何数据。
-
Accept-Encoding:这将告诉web服务器 当前使用的浏览器支持什么类型的压缩方法,这样数据就可以变小以便通过互联网进行传输。
-
Cookie:Cookie 是发送到服务器以帮助记住你的信息的数据。
-
-
常见的响应头
以下是发出请求后从服务器端返回给浏览器客户端的标头信息。
-
Set-Cookie:表示浏览器端要存储的Cookie信息,之后每次浏览器发出请求时,Cookie值都会发送回 Web 服务器。
-
Cache-Control:在再次请求之前,响应内容在浏览器缓存中将存储多长时间。
-
Content-Type:这将告诉客户端 从web服务器端所返回的数据类型,即 HTML、CSS、JavaScript、图像、PDF、视频等。使用Content-Type标头,浏览器才能知道如何处理数据。
-
Content-Encoding:在通过 Internet 发送数据时,web服务器将使用什么方法压缩数据以使其更小。
-
-
-
Cookies
Cookie是存储在你的计算机上的一小段数据。 当你从web服务器收到“Set-Cookie”标头时,对应的Cookie信息将被浏览器保存,然后,你发出的每一个进一步请求,都会将 Cookie 数据发送回web服务器。 由于 HTTP 是无状态的(不跟踪你之前的请求),所以 Cookie 可用于提醒web服务器你的身份、网站的一些个人设置或者你以前是否访问过该网站。
让我们看一下下面这个 HTTP 请求示例:
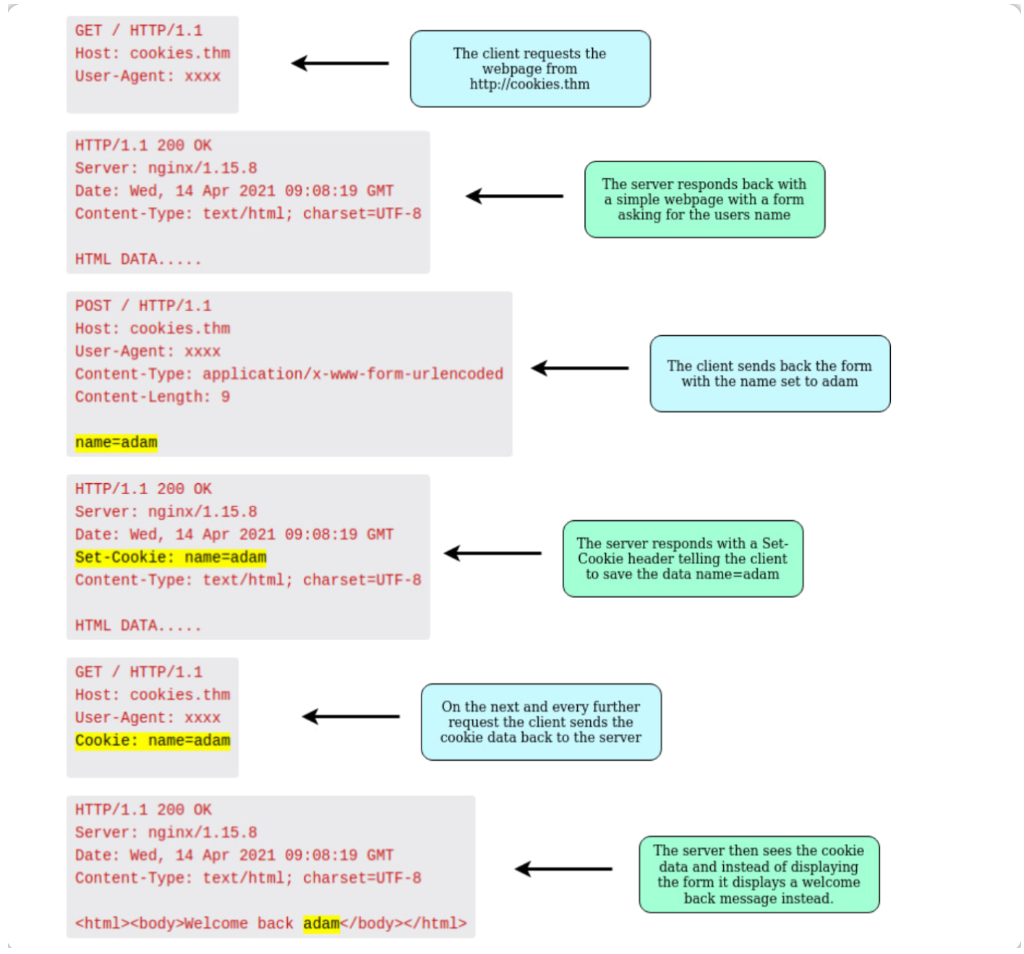
Cookie 可用于多种用途,但最常用于网站身份验证。 cookie 值通常不会是一个可以让你直接看到密码的明文字符串,而会是一个令牌-token(具有不容易被猜到的唯一密码)。
-
查看你的 Cookie
可以使用浏览器中的开发者工具查看你的浏览器向网站发送了哪些 cookie。
打开开发人员工具后,单击“网络”选项卡。 此选项卡将向你显示你的浏览器已请求的所有资源的列表,你可以单击每一个子项以查看请求和响应的详细分类信息。 如果你的浏览器发送了 cookie,你将在请求消息的“Cookie”选项卡上看到具体的cookie内容。
-
Web基础-part 3
-
How websites work
-
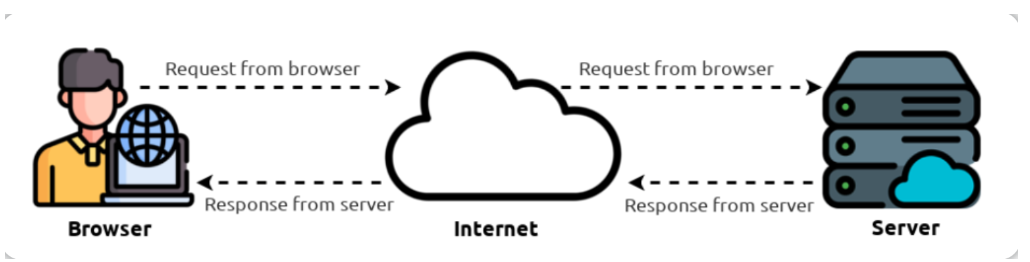
当你访问一个网站时,浏览器(如Safari或谷歌Chrome)会向web服务器发出请求,这将询问有关你正在访问的页面的信息,然后web服务器将以“用来显示页面的数据”响应你的浏览器;web服务器是一些位置在世界上其他地方的 并且 能够处理你的请求的专用计算机。
-
一个网站有两个主要组成部分:
-
前端(客户端)-你的浏览器呈现(渲染)网站的方式。
-
后端(服务器端)-处理你的请求消息并返回响应消息的服务器。
- 在你的浏览器向web服务器发出请求的过程中 还涉及许多其他过程,但现在,我们只需要了解:我们能够向web服务器发出请求,web服务器将响应我们的浏览器以提供一些用于向我们呈现信息的数据。
-
-
HTML
网站的网页内容主要使用以下内容创建:
-
HTML:用于构建网站并定义其结构;
-
CSS:通过添加样式选项使网站看起来更漂亮;
-
JavaScript: 使用交互性脚本在网站页面上实现复杂的功能。
超文本标记语言(HTML-HyperText Markup Language)是专门用于编写网站的网页内容的语言,元素-Elements (也被称为标签-Tags)是HTML页面的构建模块,它能告诉浏览器如何显示网页内容。下面的代码片段显示了一个简单的HTML文档,HTML的结构对于每个网站来说都是一样的:
<!DOCTYPE html> <html> <head> <title>Page Title</title> </head> <body> <h1>Example Heading</h1> <p>Example paragraph..</p> </body> </html>示例中的HTML结构(如上图所示)包含了以下组件:
-
<!DOCTYPE html>定义了此页面是HTML5文档,这有助于在不同浏览器之间实现标准化,并告诉浏览器使用HTML5来解释页面。 -
<html>元素是是HTML页面的根元素——所有其他元素都在这个元素之后。 -
<head>元素包含了关于页面的信息(例如页面标题)。 <body>元素定义了HTML文档的正文,浏览器中只显示body(主体)内部的内容。<h1>元素定义了一个大标题(heading)。-
<p>元素定义了一个段落(paragraph)。 - 还有许多可用于不同目的的其他HTML元素(标签),例如,按钮(
<button>)、图像(<img>)、列表等标签。
元素(标签)可以包含一些属性,比如class属性可以用来设置一个元素的样式(例如设置段落标签的颜色)–
<p class="bold-text">,还有src属性可用于在图像标签中指定图像的位置–<img src="img/cat.jpg">。一个元素(标签)可以有多个属性,并且每个属性都有自己独特的用途,例如
<p attribute1="value1" attribute2="value2">元素可以有id属性(例如
<p id="example">),id在元素的属性中具有唯一性。id属性不同于class属性(多个元素可以使用同一个class属性),不同的元素会有不同的id来唯一地标识它们,元素的id属性主要用于样式化以及提供给JavaScript脚本识别。你可以通过右键单击网页并选择“查看页面源代码”(Chrome)选项 或者选择“显示页面源代码”(Safari)选项,以此来查看任何网站网页的HTML页面。
tips:本小节只是简单介绍一下用于网站运行的HTML,关于HTML的更多教程请参考—— https://www.runoob.com/html/html-tutorial.html 。
-
-
JavaScript
JavaScript (JS)是世界上最流行的编码语言之一,它允许网站的页面变得具有交互性。HTML用于创建网站的结构和内容,而JavaScript用于控制网页的功能——没有JavaScript,页面就不会有交互元素,将永远是静态的;在网站页面上发生特定事件时,JS可以对应地实时动态更新网站页面,比如我们可以使用JS来设置——每当用户单击按钮,则动态改变按钮的样式或者动态显示移动动画等等。
JavaScript可以被添加到网站的页面源代码中,JS代码可以通过以下两种方式进行加载:
-
可以通过
<script></script>标签直接进行加载,将具体的JS代码包含在script标签之间即可; -
通过src属性远程包含js脚本文件:
<script src="/location/of/javascript_file.js"></script>。
下面的JavaScript代码能够在网站的页面上找到id为“demo”的HTML元素,并能将元素内容更改为“Hack The Planet”:
document.getElementById("demo").innerHTML = "Hack the Planet";通过HTML元素也可以设置事件,如“onclick”或“onhover”,当事件发生时则会自动执行和事件对应的JS代码;例如,下面的代码能够将带有“demo”ID的元素的文本内容更改为“Button Clicked”:
<button onclick='document.getElementById("demo").innerHTML = "Button Clicked";'>Click Me!</button>在实际情况中,“onclick”事件一般会在JavaScript脚本标签中定义,而不是直接通过HTML元素定义。
tips:本小节只是简单介绍一下用于网站运行的JS,关于JavaScript的更多教程请参考—— https://www.runoob.com/js/js-tutorial.html 。
-
-
Sensitive Data Exposure
敏感数据泄露是指网站没有正确保护(或删除)用户的敏感明文信息(通常是在站点的前端源代码中找到一些敏感数据)。
我们知道,网站是用许多HTML元素(标签)构建的,所有这些元素我们都可以通过浏览器中的“viewing the page source”选项来查看,而网站开发人员可能会忘记删除登录凭据、网站隐私部分的隐藏链接或其他以HTML/JavaScript形式显示的敏感数据——也就是说,我们可以尝试通过浏览器的“viewing the page source”选项来发现一些敏感数据。
敏感信息可能会被潜在地利用,从而进一步扩大攻击者对web应用程序不同部分的访问权限;例如,网站的页面源代码中可能存在带有临时登录凭据的HTML注释,当你查看页面的源代码时就可能发现这一点,这使得你可以使用所发现的凭据在应用程序的其他地方实现登录(或者更糟,将凭据用于访问站点的其他后端组件)。
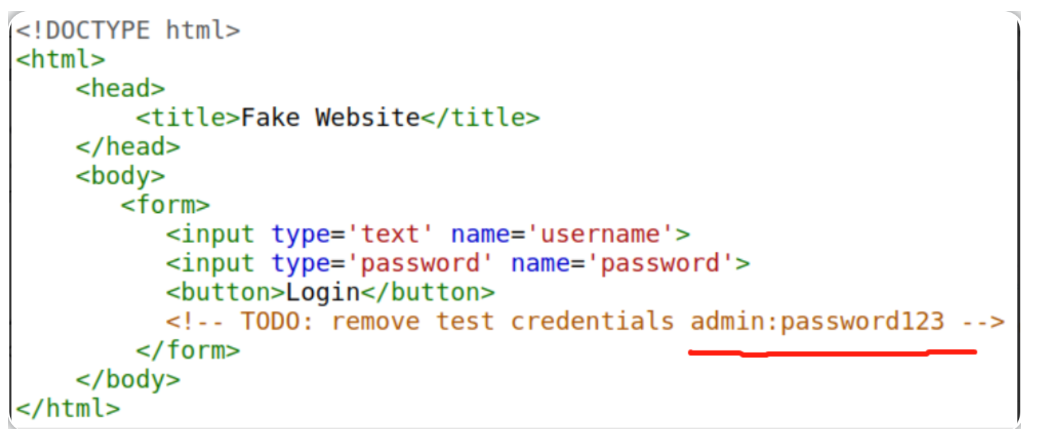
无论何时评估web应用程序的安全性问题,首先应该做的事情之一就是检查网站的页面源代码,看看是否可以找到任何暴露的登录凭据或隐藏的链接。
-
HTML Injection
HTML注入是一种漏洞(发生在客户端侧),这会将未经过滤的用户输入直接显示在网站页面上。如果一个网站未能过滤用户输入(过滤用户输入到网站的任何“恶意”文本),并且该输入能被显示在网站页面上,那么攻击者就可以针对易受攻击的网站实现HTML代码注入操作。
输入消毒(即过滤恶意输入)对于保持网站安全性非常重要,因为用户输入到网站的信息通常会用于其他前端或者后端的功能实现;比如,有一类漏洞是数据库注入漏洞,如果存在这种漏洞——你就可以通过控制SQL查询的输入来操作数据库并查找其中的数据,从而实现以另一个用户的身份登录网站。
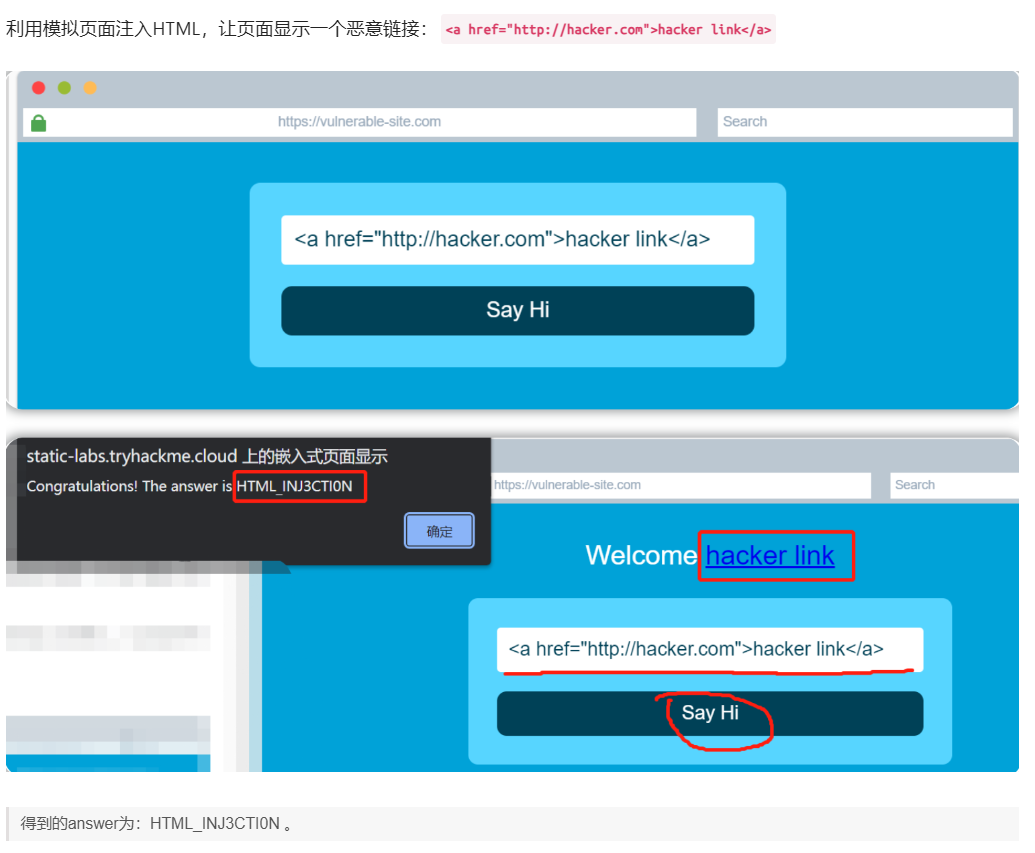
当用户可以控制如何显示他们的输入内容时,用户就可以向网站提交HTML(或JavaScript)代码,而浏览器就可能在网站页面中使用这些代码,从而允许用户能够控制网站页面的外观和功能。

上图显示了表单如何将文本输出到网站页面:无论用户在“What’s your name”的输入框中输入什么,用户所输入的内容都将传递给网站的JavaScript函数,然后输出结果将被显示在网站页面上;这意味着用户能够在输入框中添加自己构造的HTML或JavaScript代码,而这些代码将生效并能附加相关结果以显示在网站页面上。
一般的安全规则是“永远不要相信用户输入”。为了防止用户的恶意输入影响网站的正常功能,网站开发人员应该在使用JavaScript函数之前对用户所输入的所有内容进行消毒(即过滤),在这种情况下,网站开发人员应该删除“用户输入内容”中的HTML标签。
-
Test
Web基础-part 4
-
Putting It All Together
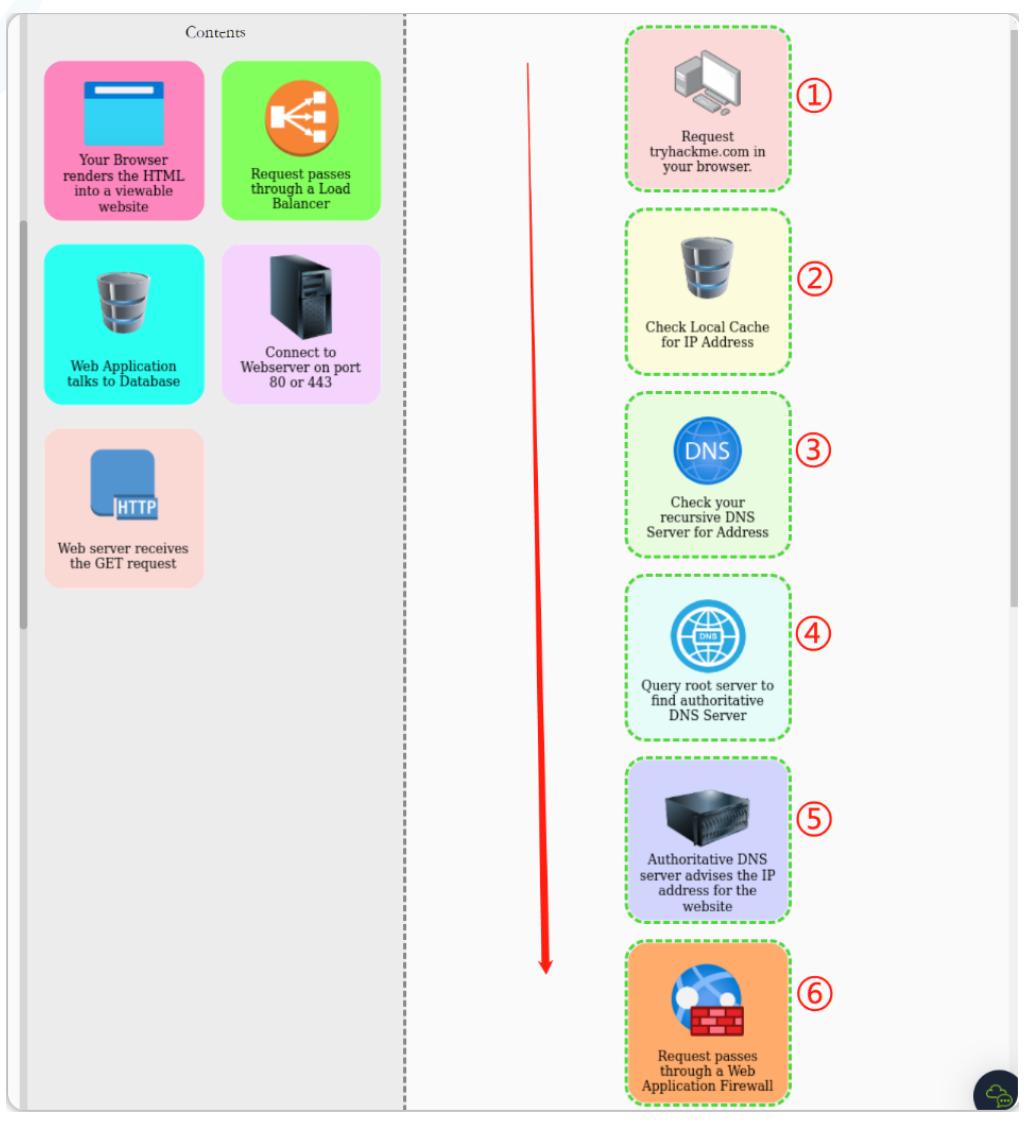
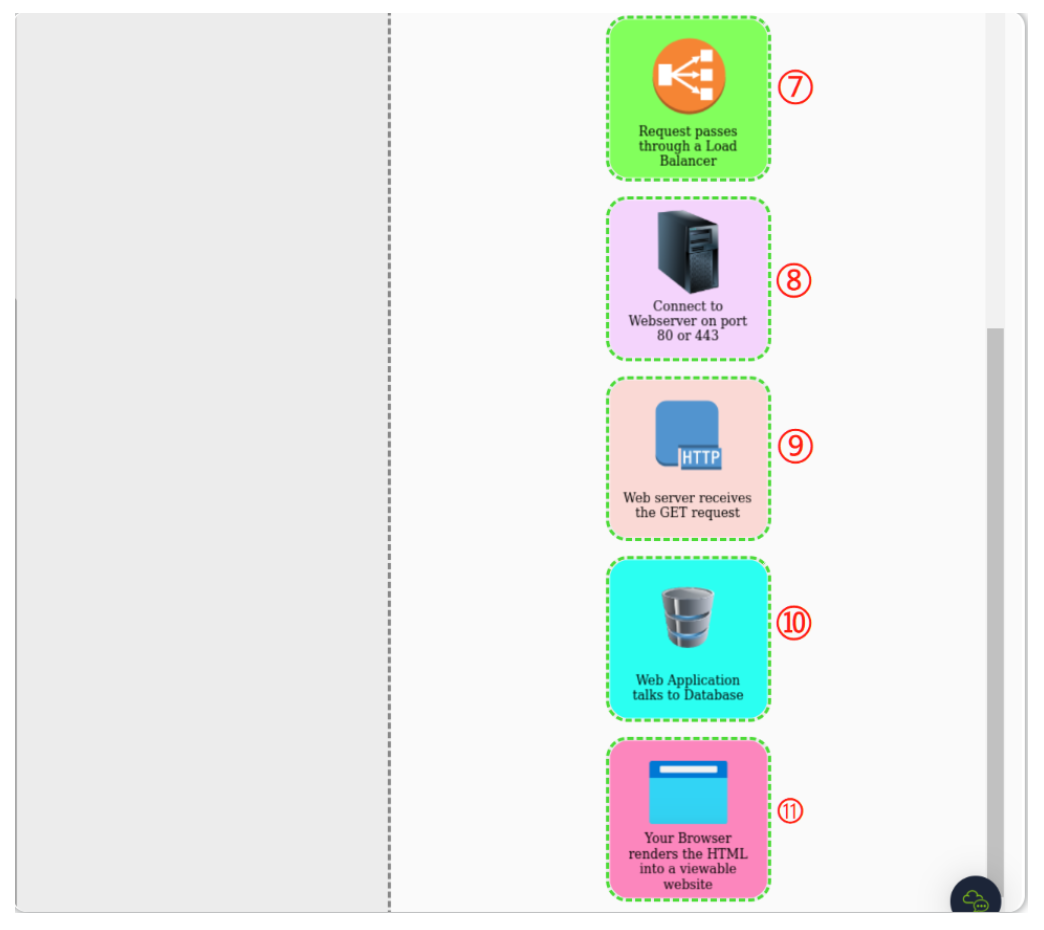
当我们在浏览器中请求网页信息时,幕后还发生了很多事情。在请求一个网站时,我们的计算机需要知道它需要与之通信的Web服务器的 IP 地址,为此,本地计算机需要使用DNS,然后,我们的计算机将使用一组被称为 HTTP 协议的特殊命令与 Web 服务器进行通信, Web 服务器随后将返回 HTML 、JavaScript 、CSS、图像文件等资源,最后,我们本地计算机的浏览器将使用这些资源 并通过正确格式化来向我们呈现网站的相关网页内容。
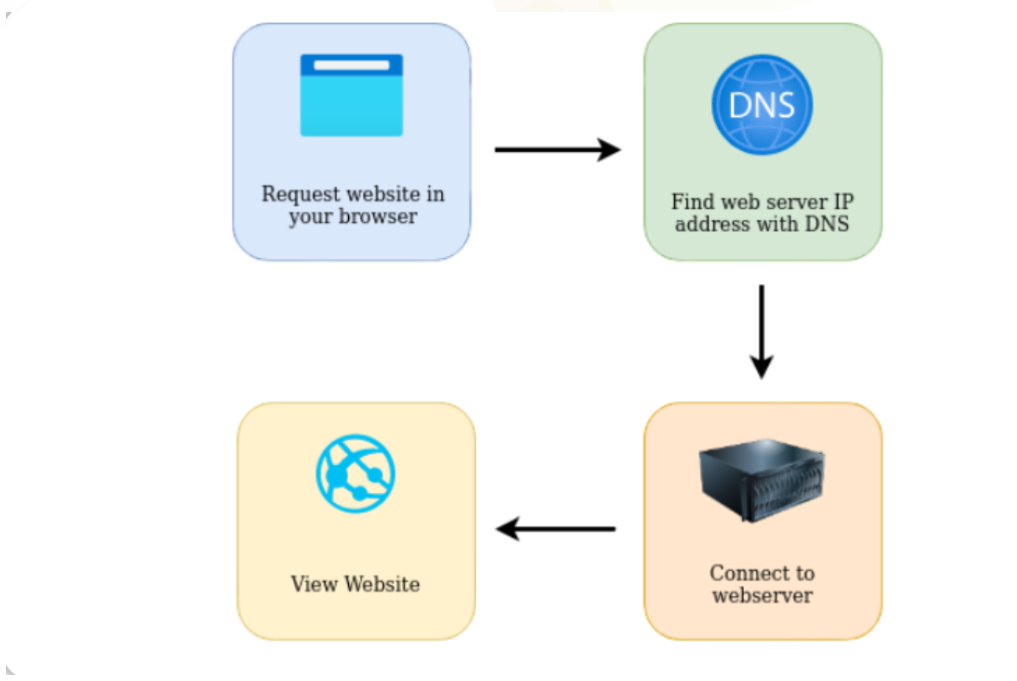
此外,还有一些其他组件可以帮助web服务更有效地运行,并提供额外的功能。
-
Other Components
-
负载均衡器(Load Balancers)
当一个网站的流量开始变得相当大,或者正在运行一个需要高可用性的应用程序时,一个web服务器也许不再能够胜任工作——此时我们就需要使用负载均衡器。
负载均衡器能提供两个主要功能:确保高流量网站可以处理负载(load);在服务器变得无响应时提供故障转移功能。
当你请求一个使用了负载均衡器的网站时,负载均衡器将首先接收到你的请求,然后它会将请求转发到它后面的多个服务器之一;在此过程中,负载均衡器会使用不同的算法来帮助决定哪台服务器最适合处理请求消息,这些算法的两个例子是:轮询(round-robin)和加权(weighted)——前者会依次将请求发送到每个服务器,后者会检查服务器当前正在处理多少请求,再将请求发送到最不繁忙的服务器。
负载均衡器还会对每个服务器执行定期检查,以确保它们能够正常运行,这被称为健康检查(health check);如果服务器没有正确响应或无响应,负载均衡器将停止向服务器发送流量,直到服务器再次正确响应为止。
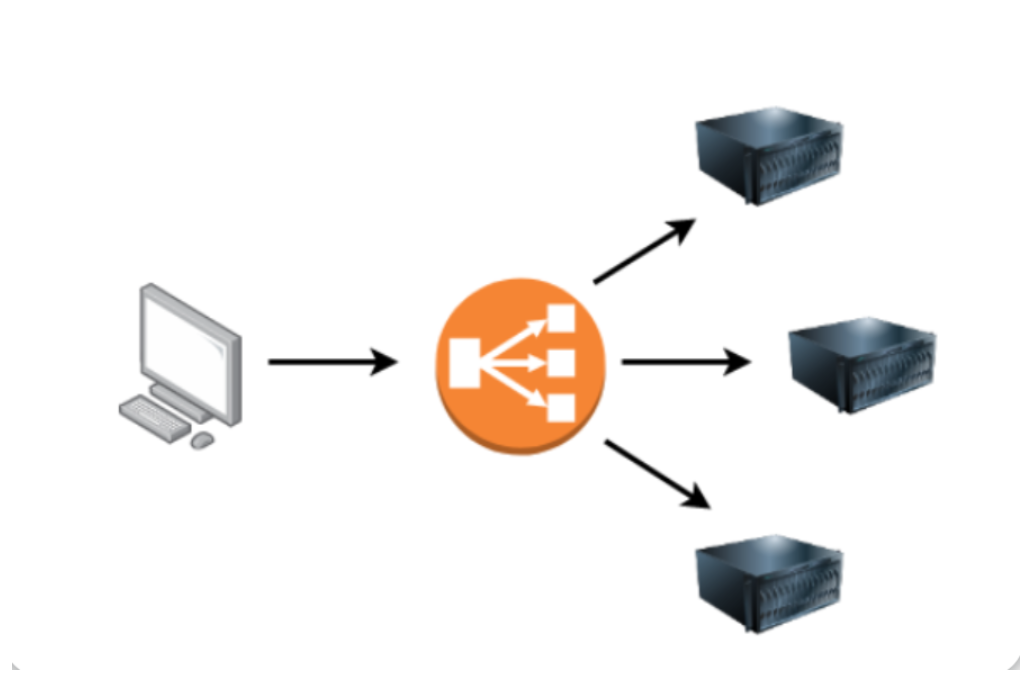
-
CDN (Content Delivery Networks)
CDN是一个很好的资源,它可以帮助降低“繁忙网站”的流量压力。CND允许网站管理者托管网站的一些静态文件,如JavaScript, CSS,图像,视频等,使用CDN能将网站静态文件托管在世界各地的数千台服务器上。每当用户请求一个被托管的文件时,CDN就会计算出最近的服务器的物理位置,并将用户的请求发送到那里,而不是发送到遥远的世界另一端。
-
数据库(Databases)
每个网站通常都需要一种为用户存储信息的方法,这就需要使用数据库。
web服务器可以与数据库进行通信,从而能将数据存储到数据库中以及能从数据库中提取数据。数据库可以是简单的纯文本文件,也可以是 由能够提供速度和弹性的多台服务器组成的复杂集群,一些常见的数据库有:MySQL,MSSQL,MongoDB,GraphQL,Postgres等,每一种数据库都有其具体的特性。
-
WAF (Web Application Firewall)
Web应用程序防火墙(WAF-Web Application Firewall)位于你的web请求和web服务器之间,它的主要目的是保护web服务器免受黑客攻击或拒绝服务(DoS)攻击。
WAF能够分析带有常见攻击技术的恶意web请求,无论这些恶意请求是来自何处;WAF还会利用速率限制来检查是否有过多的网络请求正在被发送,这将只允许一个IP每秒发送一定数量的请求消息。
如果一个请求被认为是潜在的攻击载荷,那么此请求将被WAF拦截以及丢弃,这意味着此请求将永远不会被发送到web服务器。
-
-
How Web Servers Work
-
什么是Web服务器?
web服务器是一种软件,它会监听传入的请求连接,然后利用HTTP协议将web内容传递给客户端浏览器。
常见的web服务器软件有:Apache,Nginx,IIS,NodeJS等。Web服务器将从根目录下(在服务器软件的设置中定义)开始传输文件,例如,Nginx和Apache在Linux操作系统中有相同的默认根目录路径/var/www/html,而IIS在Windows操作系统中的默认根目录路径是C:\inetpub\wwwroot。
如果你向web服务器请求文件-
http://www.example.com/picture.jpg,web服务器将从它的本地硬盘驱动器中发送文件/var/www/html/picture.jpg。 -
Virtual Hosts(虚拟主机)
Web服务器可以托管多个具有不同域名的网站,为了实现这一点,Web服务器需要使用虚拟主机。web服务器软件会检查HTTP请求头中的主机名,并将其与虚拟主机进行匹配(虚拟主机只是基于文本的配置文件)。如果HTTP请求中的主机名和虚拟主机成功匹配,web服务器就会向浏览器用户提供一个正确的网站;如果没有找到匹配项,则将提供一个默认网站给浏览器用户。
虚拟主机可以将其根目录映射到web服务器的硬盘驱动器上的不同位置:
-
one.com可能被映射到web服务器中的/var/www/website_one ;
-
two.com可能被映射到web服务器中的/var/www/website_two 。
-
能在一个web服务器上托管不同网站的数量没有限制。
-
-
Static Vs Dynamic Content(静态与动态内容)
静态内容,顾名思义,是网站中永不改变的内容,常见的例子是网站的图片、javascript代码、CSS代码等,也可以包括永不更改的HTML内容。此外,静态内容文件是直接由web服务器所提供的文件,web服务器在提供这些静态文件时,无需对这些文件的内容进行任何更改。
另一方面,动态内容是网站中可以随不同的HTTP请求而发生变化的内容。以博客为例,在你的博客主页上会展示文章条目,如果你创建了一个新条目,那么博客主页就会向你显示最新的文章条目,或者以博客上的搜索页面为例,根据你搜索的单词不同,博客网站将会向你显示不同的搜索结果。
你最终看到的网站动态内容都是在所谓的后端中使用编程和脚本语言来完成的,之所以被称为后端,是因为它们所做的一切都是在幕后完成的。你不能查看网站的全部HTML源代码,也不能看到网站的后端具体发生了什么(HTML是后端处理的结果);你在浏览器中能看到的所有东西都被称为前端。
-
脚本和后端语言
服务器对后端语言所能实现的功能并没有多少限制,而这些功能的实现正是使网站与用户能够互动的原因。
常见的后端语言包括:PHP,Python,Ruby,NodeJS,Perl等;这些后端语言可以与数据库交互、调用外部服务、处理来自用户的数据……
一个非常基本的PHP示例是:你可以通过访问服务器上的PHP脚本来获得一个网站页面——
http://example.com/index.php?name=adam。如果index.php的内容如下:
<html> <body> Hello <?php echo $_GET["name"]; ?> </body> </html>它将向客户端输出以下内容:
<html> <body> Hello adam </body> </html>你能注意到在客户端看不到任何PHP代码,因为PHP代码位于后端,而后端代码所提供的交互性功能 将为(未安全创建的)web应用程序带来更多的安全问题。
-
-
Test
网站请求顺序: